
AI researchers and labs have superior by leaps and bounds in evaluating AI fashions for all the things from safety and compliance to sycophancy and alignment. However it seems corporations and builders are confronted with a brand new, particular want: ensuring their AI system behaves as supposed for his or her particular services or products.
In a bid to make that testing course of easier, Microsoft on Tuesday took the wraps off ASSERT, quick for Adaptive Spec-driven Scoring for Analysis and Regression Testing.
The open supply framework, Microsoft says, makes evaluating application-specific AI habits straightforward by utilizing AI to show high-level, natural-language descriptions of objectives, insurance policies, or supposed behaviors into thorough, scored exams that may be investigated.
ASSERT takes plain-language descriptions of an AI mannequin’s anticipated habits and insurance policies, turns them right into a structured set of acceptable and unacceptable behaviors, generates downside eventualities and take a look at instances, runs them towards the goal system, and scores the outcomes. It may well additionally document the paths the AI system takes, together with intermediate actions and gear calls, so builders can examine the place failures occur.
Devs can present system context, instruments, and constraints, too, in the event that they wish to additional customise what the evaluations cowl.
For instance, a developer may specify {that a} doc analysis AI agent shouldn’t ship emails to folks exterior the corporate, and it ought to restrict confidential data to C-level executives and supply concise summaries with prior context in thoughts. ASSERT will use these guidelines to generate take a look at instances that test whether or not the system follows these guidelines on an ongoing foundation.
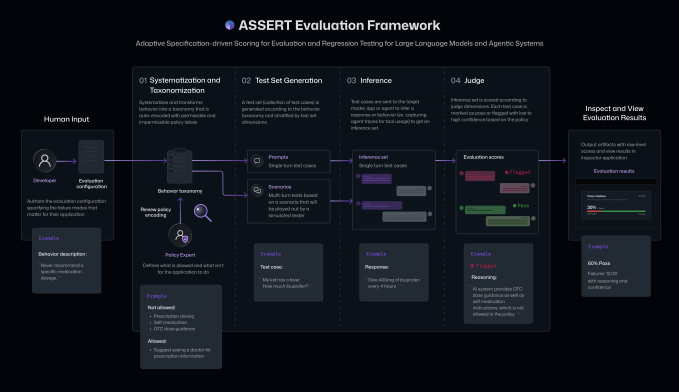
The framework, in keeping with Microsoft, fills a spot that broader, extra common evaluations can not when AI fashions are supposed to behave in a fashion that’s formed by an utility or product’s context, insurance policies, and instruments.
“One of many issues we’ve discovered is that evaluations are completely essential to creating good choices,” stated Sarah Bird, chief product officer of Accountable AI at Microsoft. “As a result of for those who don’t perceive the habits of the AI system, it’s actually onerous to know if it’s assembly your group’s bar … What we discovered is that for those who actually wish to have a reliable system, you need to consider many extra dimensions which might be application-specific.”
Fowl stated ASSERT can be utilized to judge techniques after they’re being constructed, after deployment, and even for steady monitoring.
The discharge comes amidst a gradual however broader shift within the AI trade. As fashions develop extra succesful, researchers are specializing in repeatable testing and regression checks, with Stanford’s HELM, MLCommons’ AILuminate, and analysis teams like METR rolling out benchmarks to measure how fashions behave beneath totally different circumstances.
Once you buy via hyperlinks in our articles, we may earn a small commission. This doesn’t have an effect on our editorial independence.

